現代のAWSシステムにおいて、重要なのは単にシステムが稼働しているかどうかではありません。チームがシステム内部の挙動を可視化し、異常を早期に検知し、ユーザーに影響が及ぶ前に問題を把握できるかが重要になります。これこそがオブザーバビリティの本質です。AWSではAmazon CloudWatch がモニタリング、ロギング、アラート、運用分析を統合する中核的な役割を担います。適切に設計された CloudWatch は障害発生後にグラフを確認するためのツールではなく、日常的なシステム運用を支える基盤となります。
現代のAWSアーキテクチャにおけるCloudWatchの位置づけ
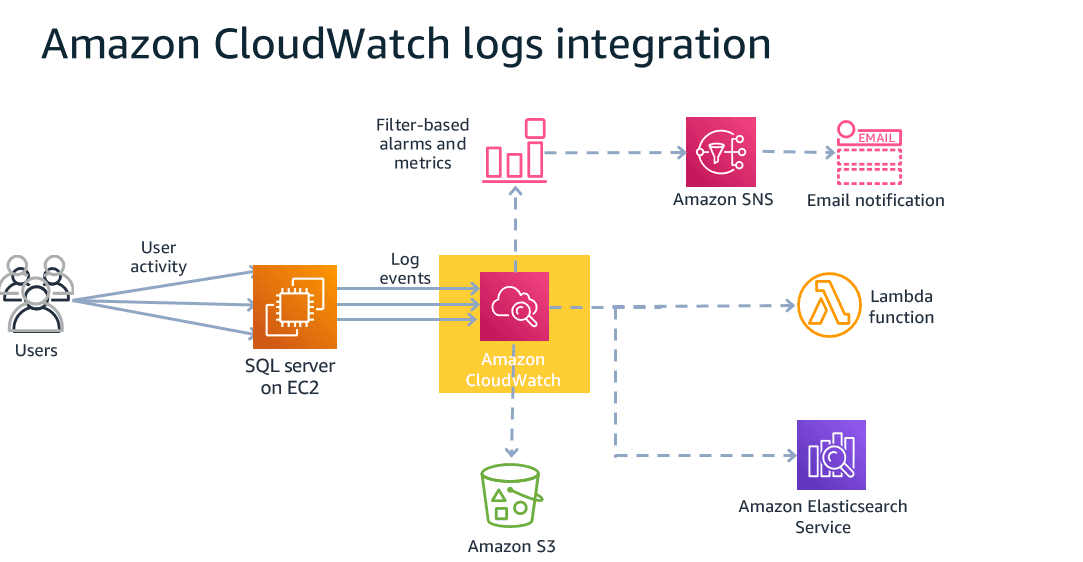
AWS環境において、Amazon CloudWatchはさまざまなリソースやアプリケーションからの運用シグナルが集約される中核を担います。メトリクス、ログ、イベントを複数サービスにわたって収集するため、単なるインフラ監視ツールにとどまりません。分散システムにおいて、可視性の対象がEC2のヘルスステータスやデータベースの負荷に限定されない点が重要です。チームにはサービス、ランタイム、依存関係全体にわたるシステム全体の挙動を、より明確に把握する必要性があります。そのため、AWS CloudWatchによるオブザーバビリティは単なる監視ダッシュボードではなく、統合されたオブザーバビリティレイヤーとして理解すべきものです。
従来のモニタリングはCPU、メモリ、ディスク、ネットワークといったインフラ指標に焦点を当てがちです。これらの指標も重要ですが、クラウドネイティブなシステムでは、それだけでは不十分なケースが多々あります。例えば、CPU使用率が正常でも、下流サービスの遅延が原因でレイテンシが悪化している場合があります。設定変更後にエラー率が上昇しても、インフラ指標には異常が現れないこともあります。ここで重要になるのが、リソースが健全かだけでなく、システムが実際の条件下でどう振る舞っているかを把握するオブザーバービリティの視点です。
この幅広い視点は、主に以下の 3 つのシグナルで構成されます:
- メトリクス: 傾向、負荷、レイテンシ、エラーパターンの可視化
- ログ: イベントおよび詳細な実行データの記録
- トレース: 複数コンポーネントをまたぐリクエストの追跡
CloudWatchはCloudWatch MetricsおよびCloudWatch Logsを通じて、最初の2つを直接カバーします。AWS X-Rayなどのサービスと組み合わせることで、リクエストトレースの深堀りも可能になります。これこそが、マイクロサービス、コンテナ、サーバーレスを基盤とした現代のアーキテクチャにおいて、AWS CloudWatchによるオブザーバビリティが有用となる理由です。トレース機能はCloudWatchが提供する幅広い可視化ツールと組み合わせることで、さらに効果を発揮します。AWS X-Rayはサービス間でのリクエストレベルのトレースを既に提供していますが、CloudWatch ServiceLensを活用すれば、これらのトレースをメトリクスやログと統合し、単一の運用ビューに集約できます。ダッシュボード間を行き来することなく、チームはサービスマップ、レイテンシの急増、関連ログを一つのインターフェースで確認可能です。
例えば、APIレイテンシのアラートが発報された場合、ServiceLensはどのダウンストリームサービスが遅延の原因となっているかを示し、関連するX-Rayトレースに直接リンクできます。これにより、問題検知から根本原因分析までのプロセスを短縮できます。
ユーザーエクスペリエンスが重要となるシステムでは、CloudWatch Real User Monitoring(RUM)がもう一つの視点を提供します。メトリクスやトレースがバックエンドの挙動を記述するのに対し、RUMはブラウザ上で実際のユーザーがアプリケーションをどのように体験しているかを計測します。ページ読み込み時間、JavaScriptエラー、地域やデバイス別のフロントエンドレイテンシなどを測定可能です。
これらのツールを連携して活用することで、オブザーバビリティの全体像がはるかに明確になります。
- メトリクスがレイテンシの増加を示す
- X-Rayトレースがリクエストのどこで遅延が発生しているかを明らかにする
- ServiceLensがサービス横断的にシグナルを関連付ける
- CloudWatch RUMが実際にユーザーがパフォーマンス低下を体験しているかを示す
このように、チームはインフラの可視性から、バックエンドシステムと実際のユーザーインタラクションの両方を含む、エンドツーエンドの完全なオブザーバビリティへと移行できます。
インフラ指標では反映オブザーバビリティ捉えきれないビジネスシグナルをカスタムメトリクスで計測
EC2、RDS、ALB、LambdaなどのAWSサービスは標準メトリクスをCloudWatchに自動的に送信します。これらのメトリクスは有用ですが、主にリソースの状態を記述するものです。実際のシステムでは、多くの深刻な問題は別の場所から始まります。アプリケーションレイヤーや、標準的なインフラメトリクスでは明確に把握できないビジネスロジックに起因するケースが少なくありません。ここに、カスタムメトリクスの重要性があります。
カスタムメトリクスを活用することで、アプリケーションは独自のシグナルをCloudWatchに送信できます。これにより、CPUやメモリのグラフだけでは把握できない、ビジネス活動、アプリケーションの健全性、ワークロードの負荷状況を反映させることが可能です。代表的な例としては以下が挙げられます。
- 1 分間の注文数
- 決済失敗率
- API 平均レイテンシ
- ビジネスワークフローにおけるキュー滞留数
これらのメトリクスはAWS SDKまたはCloudWatch Agentを通じて、EC2、ECS、EKS上で稼働するワークロードから送信可能です。その主な価値は単にデータ量が増えることではありません。システムおよびユーザーにとって実際に重要な事項を計測できる点にあります。多くの場合、インフラメトリクスに加えてビジネスレベルのシグナルを追加することで、AWS CloudWatchによるオブザーバビリティの有用性は大幅に向上します。
もう一つの重要な要素がディメンション設計です。メトリクスはサービス名、環境、リージョン、エンドポイントといったコンテキストで分割可能になると、その有用性が高まります。これにより、問題発生時のトラブルシューティングが格段に容易になります。ただし、ディメンションを増やしすぎると時系列の数が増加し、コスト上昇につながる可能性があります。適切な設計では、あらゆるラベルを必須とするのではなく、分析の深さとコスト意識のバランスを取ることが重要です。
AWS CloudWatchによるオブザーバビリティを設計する際にはコスト管理も重要な検討事項の一つです。CloudWatch は非常に強力なサービスですが、メトリクスやログを明確な方針なく収集した場合、運用コストが高額になり得ます。
コストに最も影響を与える2つの領域は以下の通りです。
- ログの取り込みおよび保存
大量のアプリケーションログは取り込みコストを急速に増加させる可能性があります。適切なログ保持ポリシーを設定することで、ストレージの増加を抑制できます。例えば、運用ログは7〜30日間の保持で十分な場合が多い一方、監査ログはより長期の保持が必要となるケースがあります。また、必要に応じて古いログをAmazon S3にエクスポートし、低コストでの長期保存を実現することも可能です。 - 多数のディメンションを持つカスタムメトリクス
メトリクス名とディメンションのユニークな組み合わせごとに、CloudWatch内に新しい時系列が作成されます。サービス、エンドポイント、環境、リージョン、バージョンといったラベルを同時に多数含めると、時系列の数が急激に増加する可能性があります。これによりコストが上昇するだけでなく、ダッシュボードの可読性も低下します。 - メトリクスの送信頻度も考慮すべき要素です。多くのワークロードにおいて、1秒ごとの高解像度メトリクス送信は不要な場合があります。多くのケースでは、30秒または60秒間隔での送信でも、運用上の可視性を十分に確保しつつ、メトリクス量を大幅に削減できます。
したがって、実践的なオブザーバビリティ設計では、可視性とコスト意識のバランスを取ることが重要です。チームはあらゆるメトリクスやログイベントをデフォルトで送信するのではなく、運用において真に価値のあるシグナルを意図的に選定すべきです。
カスタムメトリクスを設計する実践的なアプローチとして、Service Level Indicator(サービスレベル指標)から始める方法があります。チームが最も重視するシグナルは一般的にレイテンシ、エラーレート、スループットです。ここから出発し、適切なカスタムメトリクスを送信し、汎用的なインフライベントではなく、SLOの閾値に基づいてアラートを構築できます。このアプローチにより、オブザーバビリティレイヤーは実際のサービス品質とより密接に連動します。また、問題がユーザーに認識される前に、異常な挙動を早期に検知する支援にもなります。
単なるサービス単位ではなく、運用コンテキストに沿ったダッシュボードの構築
有用なダッシュボードは一つの問いに迅速に答えられるべきです。何が問題で、次にどこを確認すべきか。単に汎用的なインフラグラフを表示するだけでは、むしろそのプロセスを遅らせる結果になりかねません。
より効果的なCloudWatchダッシュボードは一般的に以下のようなコンテキストに沿って構築されます。
- 本番環境の健全性: リクエストボリューム、エラーレート、レイテンシ、飽和度
- ビジネスフロー: 成功した注文、失敗した決済、キュー深度、リトライ回数
- 環境別ビュー: 本番、ステージング、リージョン固有の挙動
- サービスドメイン: チェックアウト、認証、検索、バックグラウンド処理
例えば、ECサイト向けのダッシュボードは、以下のシグナルを一箇所に集約することで、より有用になります。
- ALBのリクエスト数
- 成功した注文数
- 5xxエラーレート
- 決済APIのレイテンシ
- バックグラウンドジョブのキュー深度
これはAWS CloudWatchによるオブザーバビリティにより適合しています。なぜなら、チームはリソースコンテキストだけでなく、ビジネスコンテキストの中でシステム挙動を読み取れるからです。
CloudWatchはメトリクス計算もサポートしており、これは表面的な印象以上に重要な機能です。生数値をプロットするだけでなく、チームは複数メトリクスからエラーレートといったシグナルを算出できます。
メトリクス計算は複数生のメトリクスから運用シグナルを導出したい場合に特に有用です。各メトリクスを個別にプロットするのではなく、CloudWatchはサービスヘルスをより適切に表す比率やパーセンテージを計算可能です。
代表的な例として、リクエストメトリクスからAPIエラーレートを算出するケースが挙げられます。システムが以下の2つのメトリクスを送信していると仮定します。
- m1 = 失敗したリクエスト数
- m2 = リクエスト総数
CloudWatchのメトリクス計算を用いると、エラーレートは以下のように算出できます。
(m1 / m2) * 100
これにより、生リクエスト数がダッシュボードやアラートで解釈しやすいパーセンテージに変換されます。例えば、算出されたエラーレートが5分間連続して2%を超えた場合にアラートが発報されるように設定可能です。
メトリクス計算は以下のような他の派生シグナルの算出にも活用できます。
- 成功率
- キャッシュヒット率
- リクエストレイテンシのパーセンタイル
- 使用率パーセンテージ
生メトリクスをより高次の指標に変換することで、ダッシュボードはより意味のあるものとなり、インシデント発生時の運用担当者の読み取りやすさが向上します。
事後対応型の監視ではなく、早期警告としてのアラート活用
ダッシュボードはチームに何が起こっているかを示します。一方、アラートは問題が悪化する前に対処することを可能にします。これはAWS CloudWatchによるオブザーバビリティにおける重要な転換点です。優れた監視とは、ユーザーからのクレーム後にスパイクを確認するだけでなく、タイムリーに対応できる十分な早期に異常挙動を検知することにあるからです。
CloudWatchアラートは以下のような実践的な用途で活用できます。
- Amazon SNSを介した通知送信
- メールまたはSlackへのアラート転送
- 自動応答のためのLambdaトリガー
- スケールアウト、サービス再起動、トラフィック切り替えなどのアクション実行
固定閾値にも依然として役割はありますが、常に十分とは限りません。時間、曜日、季節によってトラフィックが変動するシステムでは、異常検知(Anomaly Detection)の方が有用な場合があります。メトリクスを単一の静的数値と比較するのではなく、CloudWatchは時間経過に伴う通常パターンと比較可能です。これにより、予測可能なトラフィック変動を持つワークロードにおいて、ノイズの多いアラートを削減できます。
また、アラート設計も重要です。閾値設定が不適切な多数のアラートは保護ではなくノイズを生み出します。これが原因でチームはアラート疲労に陥り、最終的にアラートを無視するようになるケースもあります。より良いアプローチはアラートをサービス品質に紐付け、ユーザーに直接影響を与えるシグナルを優先し、重大度別に分類することです。目的はあらゆる事象にアラートを出すことではなく、実際に対処が必要な事象にアラートを出すことです。
CloudWatch LogsおよびLogs Insightsを活用した問題調査
メトリクスは何かがおかしいことを示しますが、ログはなぜ失敗したのかを具体的に説明する役割を果たします。分散型AWSシステムにおいて、この違いが非常に重要です。エラーレートのスパイクはダッシュボード上で即座に確認できるかもしれませんが、実際の調査はチームがエラーを特定のサービス、エンドポイント、リクエストパターン、あるいは具体的なログイベントにまで遡って追跡できて初めて始まります。ここに、CloudWatch Logsが単なるログ保存ではなく、真のオブザーバビリティの一部となる理由があります。
CloudWatch Logs Insightsは生ログを検索可能で構造化された形式に変換することで、この調査を大幅に高速化します。ログストリームを一つずつスクロールするのではなく、チームはログをクエリし、フィールドでフィルタリングし、イベントをグルーピングし、手動では発見に時間のかかるパターンを表面化できます。これはログが複数コンポーネントに分散し、根本原因が一箇所からは明らかにならないマイクロサービス環境において、特に有用です。適切なクエリにより、どのエンドポイントが最も頻繁に失敗しているか、どのサービスが異常なエラーを出力しているか、あるいは急激なトラフィックパターンが特定のソースに関連しているかを迅速に把握できます。
また、これはそもそもログがどのように記述されているかにも依存します。構造化されたJSONログはプレーンテキストログに比べて解析およびクエリが容易です。特に、エンドポイント、ステータスコード、サービス名、リクエスト識別子でフィルタリングする必要がある場合にその差が顕著になります。これにより、調査の信頼性が向上し、インシデント対応中のログデータ整理に費やす時間を削減できます。保持期間も重要です。ログの保持期間が短すぎると、過去分析の精度が低下します。一方、明確なポリシーなしに長期間保持し続けると、運用上のメリットが限定的であるにもかかわらず、ストレージコストが増大します。実際にはLogs Insightsはログ構造と保持ポリシーの両方が初期段階から意図的に設計されている場合に、最も効果を発揮します。
システム設計の一部としてのオブザーバビリティ設計
CloudWatchはシステム稼働後に後付けするのではなく、アーキテクチャ設計段階から計画に組み込むことで、最大の効果を発揮します。ECSやEKS環境では、チームはCloudWatch AgentまたはFluent Bitを介してログやメトリクスを送信するのが一般的です。Lambdaベースのシステムでは、その経路の多くが既に組み込まれています。設定方法は異なりますが、設計上の問いは共通です。何か問題が発生した際に、システムは何を説明できるべきか。
この問いはツール選定に先立って検討すべき事項です。
どのメトリクスが最も重要か
すべてのメトリクスを収集する必要はありません。有用なのは、サービス品質、トラフィック挙動、障害パターンを説明するのに役立つメトリクスです。
どの程度ログを記録すべきか
ログが少なすぎると調査が遅延します。多すぎるとノイズとストレージコストが増加します。適切なレベルはインシデント分析時にチームが必要とする情報に基づいて決定すべきです。
何をアラートのトリガーとするか
アラート設計はグラフ上の技術的な変動ではなく、実際の運用リスクを反映すべきです。目的はあらゆる変動にアラートを出すことではなく、意味のある問題を早期に捉えることです。
ここからが実際の実装経験がものを言う領域です。難しいのはCloudWatchを有効化することではありません。Haposoftは実際の本番環境におけるAWS導入実績を有しており、オブザーバビリティがチームのトラブルシューティング迅速化とシステム運用の信頼性向上に不可欠であることを実感しています。だからこそ、オブザーバビリティはシステム設計の一部として扱うべきなのです。チームは事前に、後々本番環境の問いに答えるのに役立つシグナルを把握しておくべきです。この考え方が確立されれば、CloudWatchは単なる監視ツールを超え、システムの運用、デバッグ、継続的な改善を支える基盤となります。
まとめ
CloudWatchは受動的なモニタリングから能動的な運用へとチームを移行させる際に、最も大きな価値を発揮します。メトリクス、ログ、ダッシュボード、アラーム、ログ分析はいずれも重要ですが、その真価は本番環境においてこれらがどのように連携して機能するかによって決まります。適切に活用することで、AWS CloudWatch によるオブザーバビリティはユーザーに影響が及ぶ前に迅速な可視化、効率的な調査、そして早期の異常検知を可能にします。Haposoft はこのような取り組みにおける実践的なAWS導入支援の実績を有しており、AWS Select Tier Services Partnerとして認定されています。








.jpg&w=828&q=75)