Auto Scaling nhìn trên lý thuyết thì có vẻ đơn giản. Khi lưu lượng truy cập tăng, thêm máy ảo EC2 được khởi tạo. Khi lưu lượng giảm, các máy ảo bị hủy bỏ. Nhưng trong môi trường sản xuất, đây chính là giai đoạn mọi thứ bắt đầu rắc rối hơn.
Hầu hết các thất bại của Auto Scaling không đến từ bản thân cơ chế mở rộng của nó. Thất bại chỉ xảy ra bởi vì hệ thống chưa bao giờ được thiết kế để sẵn sàng cho việc các máy ảo xuất hiện và biến mất một cách tự do. Cấu hình giữa các máy bị sai lệch, dữ liệu vẫn còn nằm trên ổ cứng cục bộ, bộ cân bằng tải định tuyến traffic đến quá sớm, hoặc các máy ảo mới hoạt động không giống với các máy cũ. Khi quá trình mở rộng được kích hoạt, những điểm yếu này sẽ lập tức lộ diện.
Một thiết lập EC2 Auto Scaling ổn định phụ thuộc vào một giả định cốt lõi: bất kỳ máy ảo nào cũng có thể được thay thế bất cứ lúc nào mà không làm gián đoạn hệ thống. Bài viết này sẽ phân tích chi tiết các quyết định kiến trúc thực tế cần thiết để biến giả định đó thành hiện thực trong môi trường sản xuất thực tế.
1. Lựa chọn và phân loại Instance
Auto Scaling không thể tự sửa chữa những thiết lập cấu hình máy chủ kém hiệu quả. Nó chỉ nhân rộng sự kém hiệu quả đó lên. Khi các máy ảo mới được khởi chạy, chúng phải thực sự gia tăng năng lực xử lý hữu dụng thay vì tạo ra các nút thắt hiệu năng mới. Vì lý do này, việc lựa chọn loại instance phải bắt đầu từ việc xem xét workload hoạt động thực tế ra sao trong production, chứ không chỉ dựa trên chi phí hay thói quen sử dụng trước đây.
Các dòng instance EC2 khác nhau được tối ưu cho các đặc tính tài nguyên khác nhau, và việc ghép chúng sai với workload là một trong những nguyên nhân phổ biến nhất gây ra sự bất ổn định khi mở rộng.
So sánh các dòng Instance phổ biến
|
Dòng Instance |
Đặc tính kỹ thuật |
Workload phù hợp |
|
Compute Optimized (C) |
Tỷ lệ CPU cao hơn RAM |
Xử lý dữ liệu, Batch processing, Web server tải cao |
|
Memory Optimized (R/X) |
Tỷ lệ RAM cao hơn CPU |
In-memory database (Redis), SAP, ứng dụng Java |
|
General Purpose (M) |
Cân bằng CPU và RAM |
Backend ứng dụng, App server thông thường |
|
Burstable (T) |
Cho phép tăng cường CPU ngắn hạn |
Môi trường Dev/Staging, ứng dụng có tải ngắt quãng |
Trên môi trường production, kích thước instance nên được đánh giá lại sau khi hệ thống đã vận hành dưới tải thực tế một thời gian. Các mô hình sử dụng thực tế – CPU, bộ nhớ, lưu lượng mạng – thường khác xa so với giả định khi triển khai. Số liệu từ CloudWatch, kết hợp với AWS Compute Optimizer, là đủ để cho thấy một loại instance có đang bị thừa tài nguyên hay đã chạm ngưỡng giới hạn.
Lưu ý về dòng T (Burstable):
Trong các thiết lập Auto Scaling dựa trên CPU, các dòng T3 và T4g có thể gây rối khi CPU Credit cạn kiệt, hiệu năng sẽ giảm mạnh và các máy ảo hiển thị là "khỏe mạnh" trong khi phản hồi rất chậm chạp. Khi quá trình mở rộng được kích hoạt trong tình trạng này, Auto Scaling Group sẽ thêm vào các máy ảo cũng đang bị giới hạn hiệu năng, điều này vô tình làm tình hình trở nên tồi tệ hơn thay vì giảm tải.
Mixed Instances Policy
Để tối ưu chi phí và tăng tính sẵn sàng, sử dụng Mixed Instances Policy cho Auto Scaling Group (ASG). Cơ chế này cho phép:
- Kết hợp On-Demand (cho tải nền) và Spot Instances (cho tải biến động) để giảm 70–90% chi phí.
- Sử dụng nhiều loại instance tương đương (ví dụ: m5.large, m5a.large) để tránh rủi ro thiếu tài nguyên (capacity) tại một Availability Zone cụ thể.
2. Quản lý AMI và Nguyên tắc Hạ tầng Bất biến
Nếu bất kỳ máy ảo nào cũng có thể được thay thế bất cứ lúc nào, thì cấu hình không thể lưu trữ trên chính máy đó. Auto Scaling tạo và xóa các phiên bản liên tục. Ngay khi một hệ thống phụ thuộc vào các bản sửa lỗi thủ công hoặc các thay đổi tùy ý sẽ xảy ra hiện tượng hoạt động không đồng đều giữa các máy. Trong điều kiện lưu lượng truy cập bình thường, điều này hiếm khi xảy ra. Trong các sự kiện mở rộng hoặc thu hẹp quy mô, nó lại xảy ra – bởi vì các phiên bản mới không còn hoạt động giống như các phiên bản cũ mà chúng thay thế.
Đây là lý do tại sao AMI, chứ không phải instance, là đơn vị triển khai. Các thay đổi được thực hiện bằng cách xây dựng một ảnh mới và cho phép Auto Scaling thay thế dung lượng bằng ảnh đó. Không có gì được mặc nhiên kế thừa. Việc thay thế instance trở thành một hoạt động có kiểm soát, không phải là nguồn cơn bất ngờ.
- Tinh chỉnh bảo mật (Hardening)
Cập nhật hệ điều hành, bản vá bảo mật và loại bỏ các dịch vụ không cần thiết được thực hiện một lần duy nhất trong AMI. Mỗi instance mới đều khởi động từ một nền tảng cơ sở an toàn và đã được biết trước. - Tích hợp sẵn tác tử (Agent integration)
AWS Systems Manager, CloudWatch Agent, và các công cụ chuyển tiếp log được tích hợp sẵn vào chính image đó. Các instance có thể được giám sát và quản lý ngay từ khi chúng khởi chạy, không cần ai phải đăng nhập vào để "hoàn tất cài đặt". - Quản lý phiên bản (Versioning)
AMI được gắn phiên bản rõ ràng và được tham chiếu qua tag. Thao tác rollback được thực hiện bằng cách chuyển đổi phiên bản, chứ không phải bằng cách sửa chữa từng máy một cách thủ công.
3. Chiến lược Lưu trữ cho Mô hình Phi trạng thái
Trạng thái cục bộ không còn đúng với giả định đó. Đây là lý do tại sao nhiều hệ thống được thiết kế tốt lại âm thầm vi phạm mô hình mở rộng của chính chúng. Dữ liệu được ghi vào ổ đĩa cục bộ, bộ nhớ đệm được coi là bền vững, hoặc các tệp được giả định là vẫn tồn tại sau khi khởi động lại. Không có giả định nào trong số này còn đúng khi Auto Scaling bắt đầu đưa ra quyết định thay mặt bạn.
Để đảm bảo các instance có thể thay thế được, hệ thống phải được thiết kế theo kiểu stateless một cách rõ ràng.
- Các loại ổ đĩa EBS và gp3
EBS phù hợp cho các ổ đĩa khởi động và nhu cầu ứng dụng tạm thời, nhưng không phù hợp cho trạng thái hệ thống lâu dài. gp3 được ưa chuộng hơn vì hiệu năng không phụ thuộc vào kích thước ổ đĩa, giúp việc thay thế phiên bản trở nên dễ dự đoán và tiết kiệm chi phí. - Đưa dữ liệu bền vững ra bên ngoài
Mọi dữ liệu cần phải tồn tại sau khi phiên bản bị chấm dứt sẽ được chuyển ra khỏi vòng đời Auto Scaling- Chia sẻ files → Amazon EFS
- Lưu trữ đối tượng và dữ liệu tĩnh → Amazon S3
- Databases → Amazon RDS hoặc DynamoDB
- Chấp nhận việc chấm dứt hoạt động như một hành vi bình thường
Các phiên bản không được bảo vệ khỏi việc dừng hoạt động; kiến trúc mới là thứ được bảo vệ. Khi một phiên bản bị xóa, hệ thống vẫn tiếp tục hoạt động vì không có dữ liệu quan trọng nào phụ thuộc vào nó.
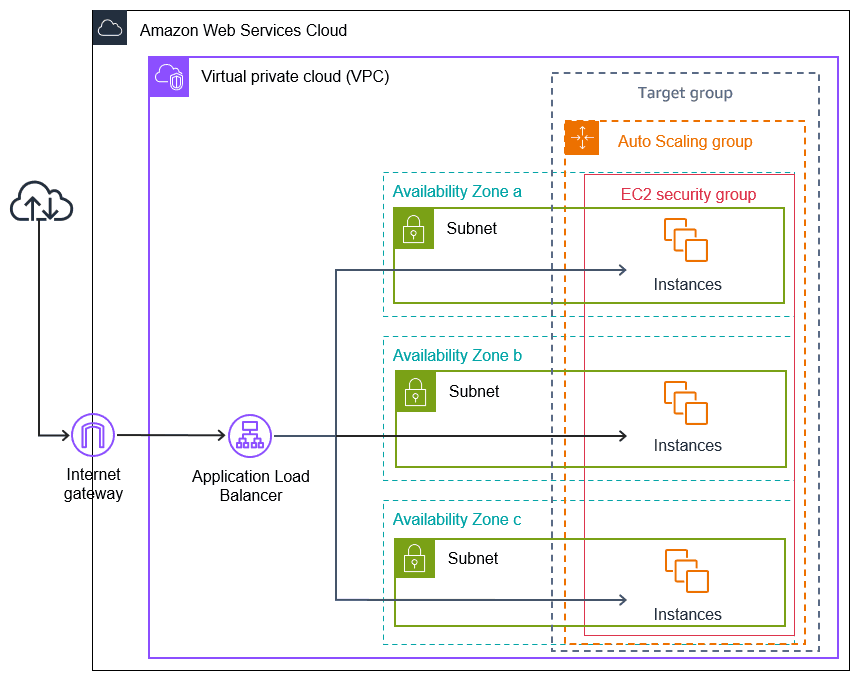
4. Thiết kế Mạng và Cân bằng Tải
Nếu bất kỳ máy ảo nào cũng có thể bị thay thế bất kỳ lúc nào, lớp mạng phải được xây dựng với giả định rằng lỗi là điều bình thường và mang tính cục bộ. Thiết kế mạng không thể coi một instance hay một Availability Zone là đáng tin cậy tuyệt đối. Auto Scaling có thể giảm capacity ở zone này trong khi tăng thêm ở zone khác. Nếu việc định tuyến traffic hoặc đánh giá tình trạng máy quá khắt khe hoặc quá sớm, việc thay thế instance sẽ biến thành lỗi dây chuyền thay vì là sự luân chuyển có kiểm soát.
- Triển khai Multi-AZ: Auto Scaling Groups nên trải rộng trên tối thiểu ba Availability Zones. Điều này đảm bảo rằng việc thay thế instance hoặc mất capacity trong một zone đơn lẻ không làm mất khả năng phục vụ traffic của toàn hệ thống. Khả năng thay thế instance chỉ hiệu quả khi phạm vi ảnh hưởng của lỗi được giới hạn ở cấp độ AZ.
- Thời gian chờ kiểm tra tình trạng: Các bộ cân bằng tải đánh giá tình trạng instance một cách máy móc. Nếu không có thời gian chờ, các instance mới khởi chạy có thể bị đánh dấu là "không hoạt động” khi ứng dụng vẫn đang trong quá trình khởi động. Điều này dẫn đến việc các instance bị hủy bỏ và thay thế liên tục, dù thực tế chẳng có lỗi gì. Một khoảng thời gian chờ hợp lý (ví dụ: 300 giây) sẽ ngăn chặn việc thay thế instance bị kích hoạt bởi hành vi khởi động thông thường.
- Security Groups: Các instance không nên bị lộ trực tiếp ra ngoài. Traffic chỉ được phép đi từ Security Group của Application Load Balancer đến cổng ứng dụng của instance. Điều này đảm bảo rằng các instance mới tham gia vào hệ thống qua cùng một lối vào được kiểm soát như các instance hiện có.
5. Các Cơ chế Auto Scaling Nâng cao
Nếu các instance có thể được thay thế một cách tự do, thì các quyết định mở rộng phải đủ chính xác để đảm bảo việc thay thế đó thực sự hữu ích thay vì khuếch đại sự bất ổn.
Việc chỉ dựa vào CPU utilization thường không đủ để đáp ứng các kịch bản traffic phức tạp. Khi hệ thống bước vào giai đoạn vận hành thực tế, các mô hình scaling đơn giản dựa trên ngưỡng cố định dần bộc lộ hạn chế, đặc biệt với workload có tính biến động cao, chu kỳ không đều hoặc yêu cầu độ ổn định nghiêm ngặt.
Để đảm bảo khả năng mở rộng linh hoạt mà vẫn kiểm soát được chi phí và độ trễ, cần áp dụng các cơ chế Auto Scaling nâng cao, cho phép hệ thống phản ứng chủ động và chính xác hơn trước sự thay đổi của traffic.
Dynamic Scaling
Dynamic Scaling cho phép hệ thống điều chỉnh capacity theo thời gian thực, tạo nền tảng cho khả năng tự phục hồi (self-healing).
Target Tracking là cơ chế phổ biến nhất. Giá trị mục tiêu được xác định bởi số liệu như mức sử dụng CPU, số lượng request, hoặc một metric tùy chỉnh của ứng dụng. Auto Scaling sẽ tự động điều chỉnh số lượng instance để giữ cho metric đó ở gần mức mục tiêu. Cách này tránh được việc sử dụng các ngưỡng cứng dễ kích hoạt các sự kiện scale-in hoặc scale-out một cách đột ngột.
Target Tracking được khuyến nghị sử dụng vì:
- Duy trì tải hệ thống ở mức ổn định và dự đoán được
- Giảm thiểu nguy cơ under-scaling (quá tải) và over-scaling (lãng phí tài nguyên)
- Đơn giản hóa cấu hình, hạn chế tuning thủ công
Để hệ thống phản ứng đủ nhanh, cần bật detailed monitoring (metric 1 phút). Điều này đặc biệt quan trọng với workload có spike ngắn nhưng biên độ lớn—độ trễ metric có thể ảnh hưởng trực tiếp đến độ ổn định dịch vụ.
Predictive Scaling
AWS sử dụng Machine Learning để phân tích dữ liệu lịch sử tối thiểu 14 ngày, từ đó dự đoán các đợt tăng tải định kỳ. Cơ chế này giúp ASG khởi tạo instance trước khi tải thực tế ập đến, giải quyết vấn đề thời gian khởi động (boot-up time).
Warm Pools
Warm Pools giải quyết khoảng cách thời gian giữa lúc khởi chạy instance và lúc nó sẵn sàng phục vụ.
- Các instance được giữ ở trạng thái "Stopped" nhưng đã cài đặt sẵn phần mềm.
- Khi quá trình mở rộng được kích hoạt, các instance này chuyển sang trạng thái "In-Service" nhanh hơn rất nhiều.
- Tốc độ thay thế instance được cải thiện mà không cần phải tăng vĩnh viễn số lượng instance đang chạy.
6. Kiểm thử và Hiệu chuẩn
Nếu các phiên bản được thiết kế để có thể thay thế tự do, hành vi mở rộng quy mô phải được kiểm tra trong điều kiện thực tế xảy ra việc thay thế. Các cấu hình Auto Scaling trông có vẻ đúng trên lý thuyết thường thất bại dưới tải thực tế. Việc kiểm tra không phải để chứng minh rằng việc mở rộng quy mô hoạt động trong điều kiện lý tưởng, mà là để làm rõ cách hệ thống hoạt động khi các phiên bản được thêm vào và loại bỏ một cách mạnh mẽ.
- Load Testing: Sử dụng các công cụ như Apache JMeter để mô phỏng các đợt tăng traffic đột biến. Mục tiêu không chỉ là kích hoạt quá trình mở rộng, mà còn để quan sát xem các instance mới có giúp hệ thống ổn định trở lại hay lại gây thêm độ trễ.
- Termination Testing: Chủ động hủy bỏ các instance để kiểm tra khả năng tự phục hồi của ASG và tính liên tục của dịch vụ tại bộ cân bằng tải.
- Cooldown Periods: Tinh chỉnh khoảng thời gian nghỉ giữa các hoạt động co giãn để tránh tình trạng "thrashing" – tức là co vào và giãn ra liên tục do các phản ứng quá nhạy. Việc thay thế instance phải là hành động có chủ đích, chứ không phải là phản ứng thái quá.
Lời kết
Xây dựng và vận hành một cụm VM hiệu quả trên AWS đòi hỏi cách tiếp cận mang tính hệ thống, trong đó các thành phần hạ tầng không được thiết kế rời rạc mà phải phối hợp nhất quán theo mục tiêu vận hành chung. Auto Scaling chỉ phát huy giá trị thực sự khi được đặt trong một kiến trúc được chuẩn hóa và tối ưu toàn diện.
Hiệu quả này đến từ sự kết hợp của nhiều yếu tố cốt lõi: lựa chọn loại instance phù hợp với đặc tính workload; sử dụng AMI bất biến để hỗ trợ triển khai, rollback và cập nhật một cách có kiểm soát; thiết kế storage và network tương thích với mô hình scale-out; và xây dựng scaling policy dựa trên dữ liệu vận hành thực tế thay vì các giả định tĩnh.
Khi các yếu tố trên được triển khai đúng và đồng bộ, Auto Scaling không chỉ giúp hệ thống thích ứng linh hoạt với biến động tải, mà còn góp phần nâng cao hiệu quả chi phí, cải thiện độ ổn định và tăng độ tin cậy cho hoạt động vận hành trong dài hạn.








