


Workloads spike, drop, and shift without warning, and fixed servers rarely keep up. AWS Lambda serverless architecture approaches this with a simple idea: run code only on events, scale instantly, and remove the burden of always-on infrastructure. It’s a model that reshapes how event-driven systems are designed and operated.
Event-driven systems depend on a few core pieces, and aws lambda serverless architecture keeps them tight and minimal. Everything starts with an event source, flows through a small, focused function, and ends in a downstream service that stores or distributes the result.
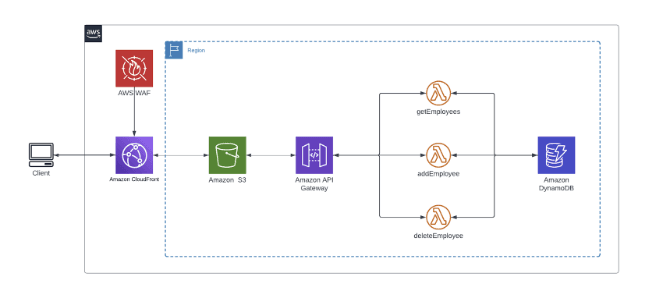
AWS Lambda is activated strictly by events. Typical sources include:
S3 when an object is created or updated
API Gateway for synchronous HTTP calls
DynamoDB Streams for row-level changes
SNS / SQS for asynchronous message handling
Kinesis / EventBridge for high-volume or scheduled events
Each trigger delivers structured context (request parameters, object keys, stream records, message payloads), allowing the function to determine the required operation without maintaining state between invocations.
Lambda functions are designed to remain small and focused. A function typically performs a single operation such as transformation, validation, computation, or routing. The architecture assumes:
Stateless execution: no in-memory persistence between invocations.
Externalized state: stored in services like S3, DynamoDB, Secrets Manager, or Parameter Store.
Short execution cycles: predictable runtime and reduced cold-start sensitivity.
Isolated environments: each invocation receives a dedicated runtime sandbox.
This separation simplifies horizontal scaling and keeps failure domains small.
Lambda versioning provides immutable snapshots of function code and configuration. Once published, a version cannot be modified. Aliases act as pointers to specific versions (e.g., prod, staging, canary), enabling controlled traffic shifting.
Typical scenarios include:
Blue/Green Deployment: switch alias from version N → N+1 in one step.
Canary Deployment: shift partial traffic to a new version.
Rollback: repoint alias back to the previous version without redeploying code.
This mechanism isolates code promotion from code packaging, making rollouts deterministic and reversible.
Lambda scales by launching separate execution environments as event volume increases. AWS handles provisioning, lifecycle, and teardown automatically. Invocation-level guarantees ensure that scaling behavior aligns with event volume without manual intervention.
Key controls include:
Reserved Concurrency — caps the maximum number of parallel executions for a function to protect downstream systems (e.g., DynamoDB, RDS, third-party APIs).
Provisioned Concurrency — keeps execution environments warm to minimize cold-start latency for latency-sensitive or high-traffic endpoints.
Burst limits — define initial scaling throughput across regions.
Reference Pipeline (S3 → Lambda → DynamoDB/SNS → Glacier)
A common pattern in aws lambda serverless architecture is event-based data processing. This pipeline supports workloads such as media ingestion (VOD), IoT telemetry, log aggregation, ETL preprocessing, and other burst-driven data flows.
Example flow:
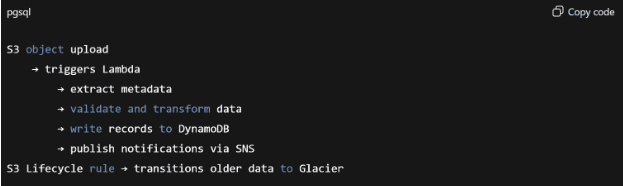
Lambda typically works alongside other AWS services to support event-driven workloads. Most integrations fall into a few recurring patterns below.
When new data lands in S3, Lambda doesn’t receive the file — it receives a compact event record that identifies what changed. Most of the logic starts by pulling the object or reading its metadata directly from the bucket. This integration is built around the idea that the arrival of data defines the start of the workflow.
Typical operations
Read the uploaded object
Run validation or content checks
Produce transformed or derivative outputs
Store metadata or results in DynamoDB or another S3 prefix
This integration behaves closer to a commit log than a file trigger. DynamoDB Streams guarantee ordered delivery per partition, and Lambda processes batches rather than single items. Failures reprocess the entire batch, so the function must be idempotent.
Use cases tend to fall into a few categories: updating read models, syncing data to external services, publishing domain events, or capturing audit trails. The “before” and “after” images included in each record make it possible to detect exactly what changed without additional queries.
Unlike S3 or Streams, the API Gateway path is synchronous. Lambda must complete within HTTP latency budgets and return a well-formed response. The function receives a full request context—headers, method, path parameters, JWT claims—and acts as the application logic behind the endpoint.
A minimal handler usually:
No queues, no retries, no batching—just request/response. This removes the need for EC2, load balancers, or container orchestration for API-level traffic.
Here Lambda isn’t reacting to an event, it’s being invoked as part of a workflow. Step Functions control timing, retries, branching, and long-running coordination. Lambda performs whatever unit of work is assigned to that state, then hands the result back to the state machine.
Workloads that fit this pattern:
multi-stage data pipelines
approval or review flows
tasks that need controlled retries
processes where orchestration is more important than compute
Each messaging service integrates with Lambda differently:
SNS delivers discrete messages for fan-out scenarios. One message → one invocation.
SQS provides queue semantics; Lambda polls, receives batches, and must delete messages explicitly on success.
EventBridge routes structured events based on rules and supports cross-account buses.
Kinesis enforces shard-level ordering, and Lambda processes batches sequentially per shard.
Depending on the source, the function may need to handle batching, ordering guarantees, partial retries, or DLQ routing. This category is the most varied because the semantics are completely different from one messaging service to another.
A practical baseline configuration that reflects typical usage patterns and cost behavior for a Lambda-based event-driven system.
A stable Lambda-based architecture usually follows a small set of practical rules that keep execution predictable and operations lightweight:
Function Structure
Keep each Lambda focused on one task (SRP).
Store configuration in environment variables for each environment (dev/staging/prod).
Execution Controls
Apply strict timeouts to prevent runaway compute and unnecessary billing.
Enable retries for async triggers and route failed events to a DLQ (SQS or SNS).
Security
Assign least-privilege IAM roles so each function can access only what it actually needs.
Observability
Send logs to CloudWatch Logs.
Use CloudWatch Metrics and X-Ray for tracing, latency analysis, and dependency visibility.
Below is a reference cost breakdown for a typical Lambda workload using the configuration above:
|
Component |
Unit Price |
Usage |
Monthly Cost |
|
Lambda Invocations |
$0.20 / 1M |
3M |
~$0.60 |
|
Lambda Compute (512 MB, 200 ms) |
~$0.0000008333 / ms |
~600M ms |
~$500 |
|
S3 Storage (with lifecycle) |
~$0.023 / GB |
~5 TB |
~$115 |
|
Total |
– |
– |
≈ $615/month |
With this model, teams typically see 40–60% lower cost compared to fixed server-based infrastructures, along with near-zero operational overhead because no servers need to be maintained or scaled manually.
Cost Optimization Tips
Lambda charges based on invocations + compute time, so smaller and shorter functions are naturally cheaper.
Event-driven triggers ensure you pay only when real work happens.
Apply multi-tier S3 storage:
Standard → Standard-IA → Glacier depending on access frequency.
A serverless architecture aws lambda works best when the system is designed around clear execution paths and predictable event handling. With the right structure in place, the platform stays stable and cost-efficient even when workloads spike unexpectedly.
Haposoft is an AWS consulting partner with hands-on experience delivering serverless systems using Lambda, API Gateway, S3, DynamoDB and Step Functions. We help teams review existing architectures, design new AWS workloads and optimize cloud cost without disrupting operations. If you need a practical, production-ready serverless architecture, Haposoft can support you from design to implementation.


.png&w=828&q=75)
